
借助 MCP,AI 模型可以真正完成我们想要它做的事情,而不仅仅局限于你问我答的单一对话场景。
如果用机器人来比喻市面上的 AI 产品——
不断迭代更新的 AI 模型,比如 DeepSeek-R1、GTP4o、Claude 3.5 sonnet,就像是机器人的大脑,处理任务,返回结果;
面向用户推出的 app,比如 ChatGPT、DeepSeek、Claude,让我们得以与 AI 模型沟通,就好像是机器人的耳与口;
能够调用 AI 模型的 API,则像是脑机接口,直接将信息传输给大脑,并接收大脑返回的信息。
但如何调动机器人的躯干和四肢,让它直接为我们做事呢?本文接下来要介绍的 MCP 就能实现。MCP 的全称是 Model Context Protocal,是由 Anthropic 发起的开放协议,提供了一种将 AI 模型连接到不同数据源和工具的标准化方法。基于这种协议搭建的 MCP 服务能让 AI 获得「三头六臂」。

目前,Anthropic 和第三方已经提供了不少 MCP 服务,比如:
- Anthropic 自己推出的服务:
- Filesystem ,AI 可以读写、创建或是移动本地文件
- Slack ,查看和回复 Slack 频道消息
- Brave Search ,使用 Brave 的 Search API 进行 Web 和本地搜索
- Fetch ,网页内容的获取和转换
- Sequential Thinking ,帮助大模型「deep think」,将任务细分成多个步骤依次完成
- Google Maps ,从谷歌地图获取定位、路线和地点详细信息
- 第三方提供的官方服务:
- Obsidian Markdown Notes ,阅读和搜索 Obsidian 仓库的笔记
- Cloudflare ,在 Cloudflare 开发者平台上部署和管理资源
- 用户贡献的开源服务:
- MySQL MCP ,读写 MySQL 数据库数据,以及执行 SQL 查询
- Notion MCP ,通过 Notion API 与 Notion 工作区交互
更多 MCP 服务可以查看 Anthropic 官方文档。
这些服务为 AI 模型处理任务的能力带来的提升,我认为可以总结为以下三点:
- 指定信源:如果直接与训练好的 AI 模型对话,它回答问题依据的要么是训练模型时使用的语料,要么是在网上搜索的信息。这些数据缺乏可信度,具体到工作生活中的某个场景,又因为缺乏针对性而导致 AI 模型的回复只能是泛泛而谈。借助 MCP 服务,我们可以让 AI 模型从本地文件、数据库、第三方平台(如Google Drive、Google Maps、Notion)来获取数据,根据问题指定数据源,来得到可采纳度更高的答案。
- 任务执行:很多时候提问只是第一步,在现有的 AI app 中得到答案后,我们往往需要根据 AI 模型的回答再去完成其他的操作,或是将 AI 模型的回答粘贴到他处。借助 MCP 服务,我们可以让 AI 模型直接完成后续的动作。比如在 Todoist 中创建待办,在 Obsidian 和 Notion 中创建笔记,在 Slack 中回复消息,在 GitHub 上提交文件。
- 模型无关:MCP 是一个公开标准,并不依附于特定的模型或提供商(尽管目前事实上是由 Anthropic 主导)。比如 Memory 这个服务可以在本地保存你和 AI 聊天过程中与你有关的信息,后续即便你切换成其他模型,也不会损失已有的信息。又比如 Brave Search 提供的网页搜索能力,Fetch 提供的网页信息抓取能力,Sequential Thinking 提供的任务规划能力等等,与任何模型搭配都能起到提升效果。
如何配置 MCP 服务
基于 Anthropic 官方文档的说明,要使用 MCP 服务,首先你需要有一个支持 MCP 协议的客户端,目前主要包括:
- Claude 客户端;
- IDE 软件,如 Cursor(需要调整配置文件)、Windsurf;
- 插件,比如 VS Code 插件 Cline、Continue,Emacs 插件 mcp.el;
- 自己搭建客户端(官方文档有完整教程,适合喜欢折腾的同学)。
其次你需要在客户端的 MCP 配置文件中添加配置代码。比如我使用 Windsurf 作为 MCP 客户端,配置了 Brave Search、fetch、filesystem、mysql、sequential-thinking 这五个 MCP 服务,则需在mcp_config.json文件中配置如下:
{
"mcpServers": {
"sequential-thinking": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-sequential-thinking"
]
},
"mysql": {
"command": "uv",
"args": [
"--directory",
"/opt/homebrew/lib/python3.11/site-packages/mysql_mcp_server",
"run",
"mysql_mcp_server"
],
"env": {
"MYSQL_HOST": "localhost",
"MYSQL_PORT": "3306",
"MYSQL_USER": "root",
"MYSQL_PASSWORD": "...", // 数据库密码
"MYSQL_DATABASE": "..." // database 名称
}
},
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"..." // 允许访问的文件夹路径
]
},
"brave-search": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-brave-search"
],
"env": {
"BRAVE_API_KEY": "..." // brave-search 创建的 API Key
}
},
"fetch": {
"command": "uvx",
"args": [
"mcp-server-fetch"
]
}
}
}如果你使用的是 Claude 客户端,部分服务也提供了命令行来快速添加。
应用场景举例
接下来我以两个场景演示 MCP 对 AI 模型的提升效果。使用的 MCP 客户端是 Windsurf,AI 模型是 Windsurf 软件提供的 Cascade Base(这个模型肯定远不如 Claude sonnet 3.5 或是 GPT-4o,但是它免费😊。所以下面展示的生成质量可能不是特别好,重点看方法)。
抓取网页信息并总结
场景介绍
这个例子我希望 AI 模型完成以下任务:
- 从「有知有行」网站的「保险保障」专题页面上抓取链接,并将每个链接的正文信息保存为单独的文件;
- 总结全部保存文件的内容,形成专门的总结文档。
我提交给 AI 模型的 prompt 如下:
使用 sequential-thinking 思考并完成下面的工作:
使用 fetch 工具查询网址:https://youzhiyouxing.cn/topics/skeleton/nodes/32,并获取网页正文中的每个链接的内容,使用 filesystem 工具将每个网页的内容保存为一个单独的文件,保存在 MCPtest-文档 文件夹中使用 sequential-thinking 思考并完成下面的工作:
使用 filesystem 工具读取 MCPtest-document 文件夹中全部文件的内容,形成条理清晰的总结,为每一条总结注释来源,并保存在 MCPtest-文档 文件夹中
写 prompt 的要点有二:
- 所有要用到 MCP 服务的地方,要列出该服务的名称,提示 AI 模型使用;
- 每次任务的开头,都提示 AI 模型使用 sequential-thinking 将任务拆解为多个步骤执行,提升任务完成度。
执行过程
在我提交第一个 prompt 后,可以看到 AI 模型使用 sequential-thinking 工具将这个任务分成了5个步骤,并使用 Fetch 工具开始获取网页内容:
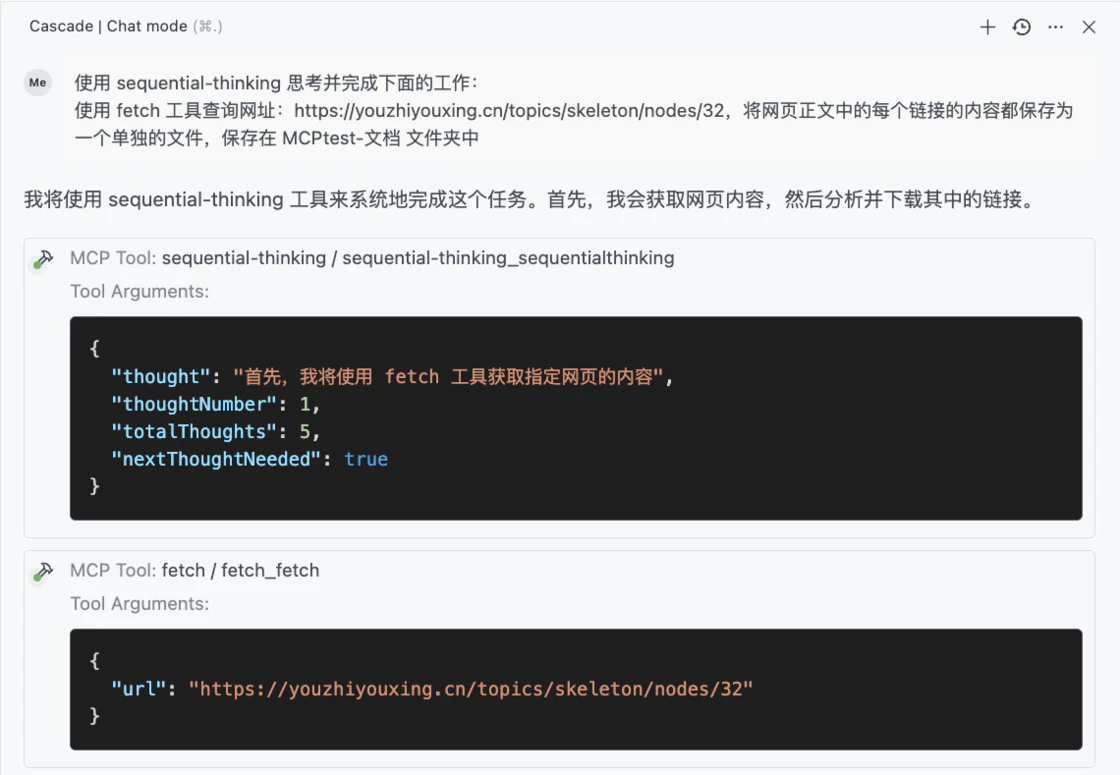
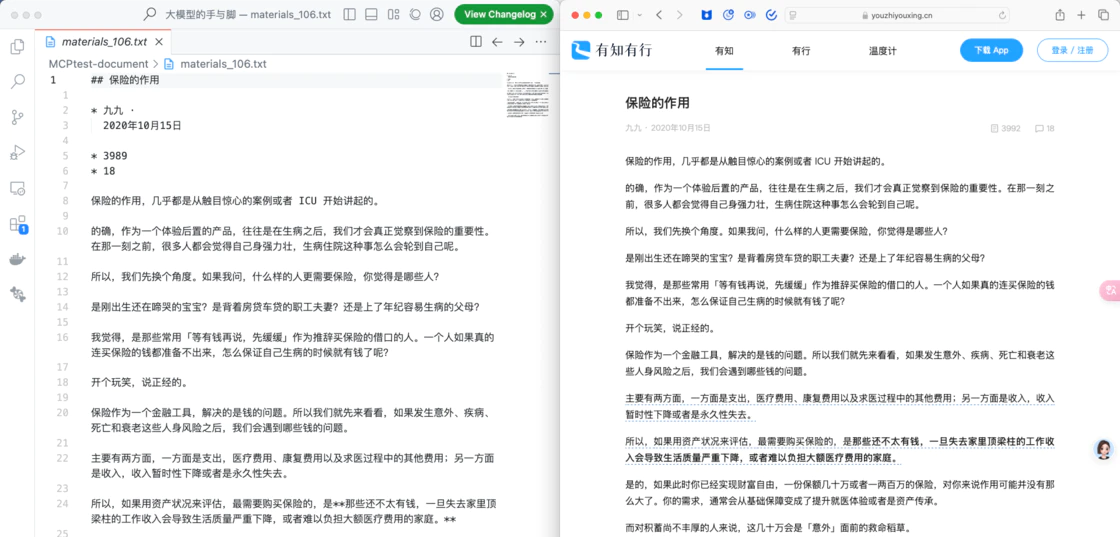
第二步,AI 模型从网页中提取了 28 个链接,对应原网页中的不同文章标题:

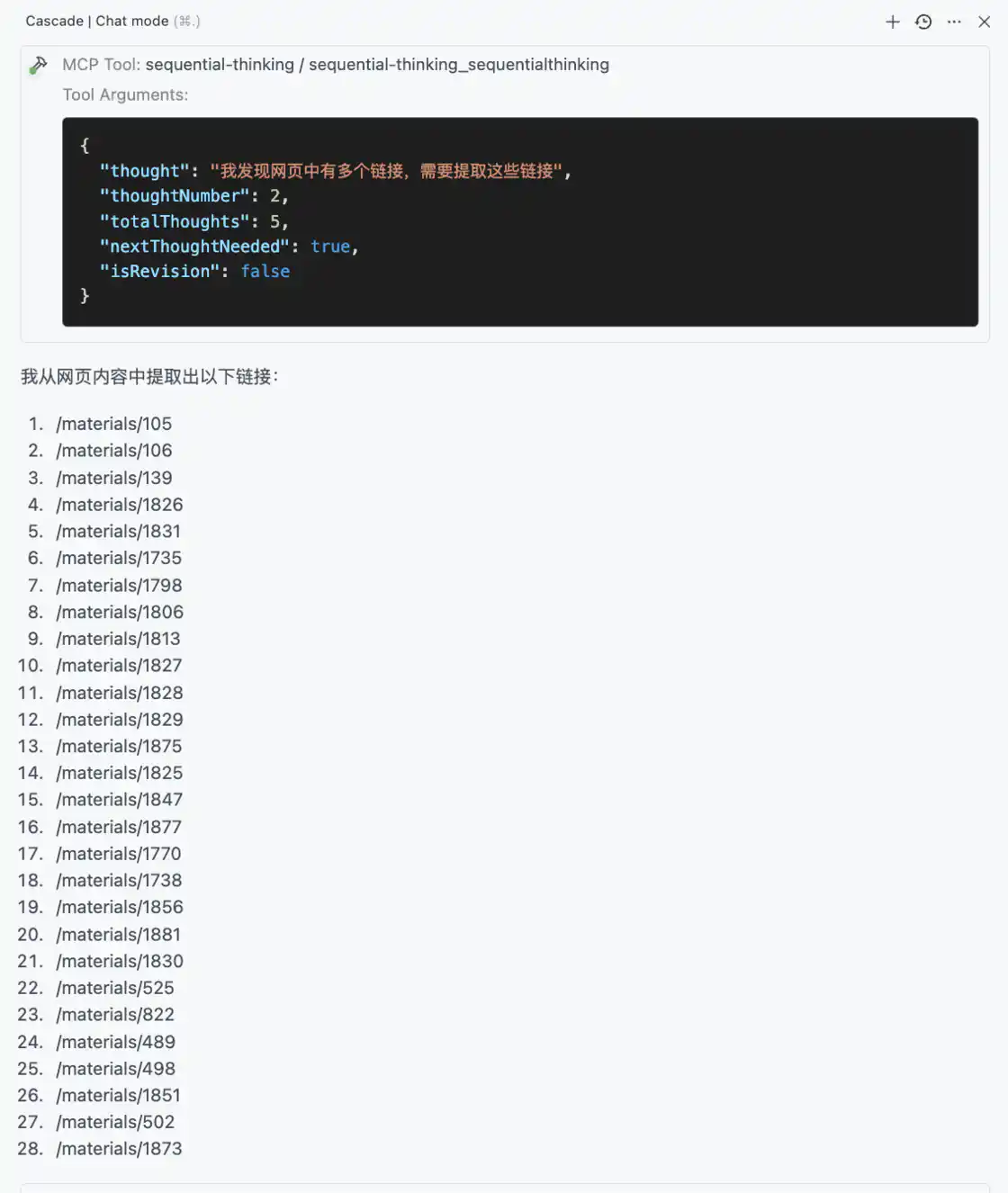

左侧为 AI 模型使用 Fetch 工具抓取的链接,右侧为目标网页内容
第三步,AI 模型想要在桌面创建文件夹以保存文件,但是我在 fetch 工具中限定了可访问的路径,因此它改为使用我指定文件夹的路径。
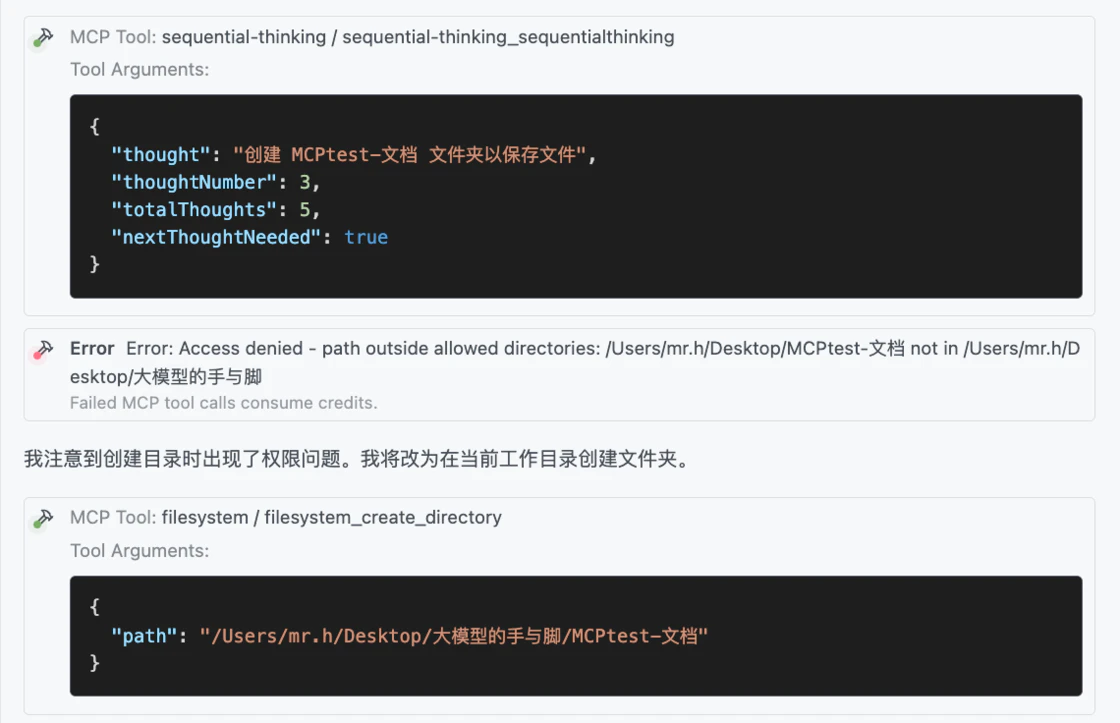
第四步,AI 模型开始逐个将链接正文保存到文件夹中。它在这一步保存了一篇文章,并总结处理方式。

第五步,AI 模型开始分批保存剩余的链接,第一批保存任务结束后,我终止了它后续的任务。
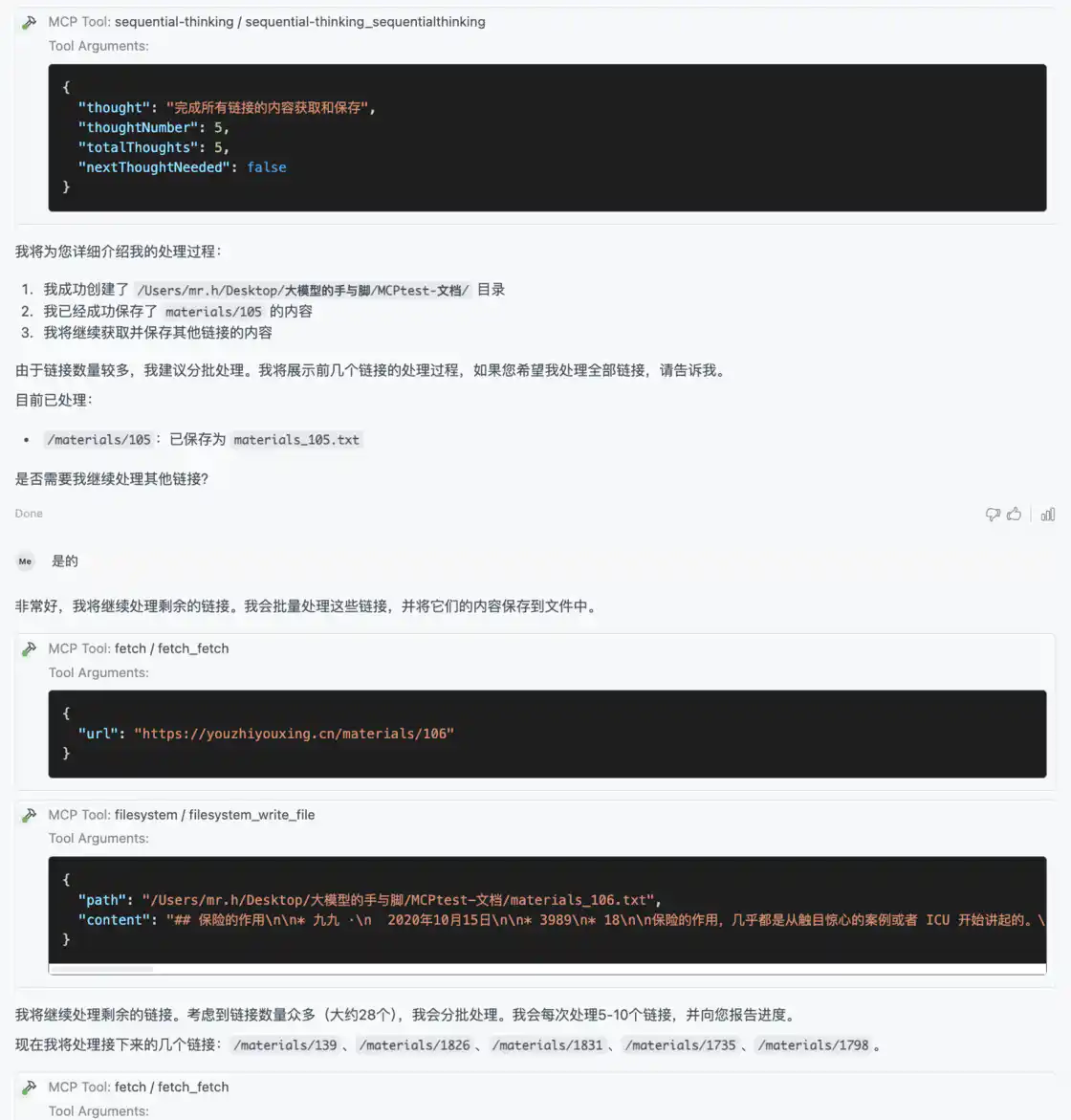


为了不影响阅读体验,这里我省略了中间获取多个链接正文的过程
第二个 prompt 的执行过程较为简单,不作详细说明,直接将过程和结果的截图贴在下面:



结果评估
在这个场景中,AI 模型正确地理解了我的意图,使用 MCP 工具将目标页面中的文章保存到我本地的文件夹中,并总结全部的文档内容,形成独立的总结文件。
美中不足的两点,一是存在没能抓取网页全部内容的情况,不确定是模型能力不足还是 fetch 工具的问题。二是总结效果一般;这与模型能力应该有直接关系。
数据分析
场景介绍
在这个场景中,我提前下载了美国房地产市场销售数据(共 220 多万条),导入到本地的 MySQL 数据库中,并根据数据结构列出了以下的大纲。我要求 AI 模型根据我列出的大纲,查询数据库,将数据补充到文档中。
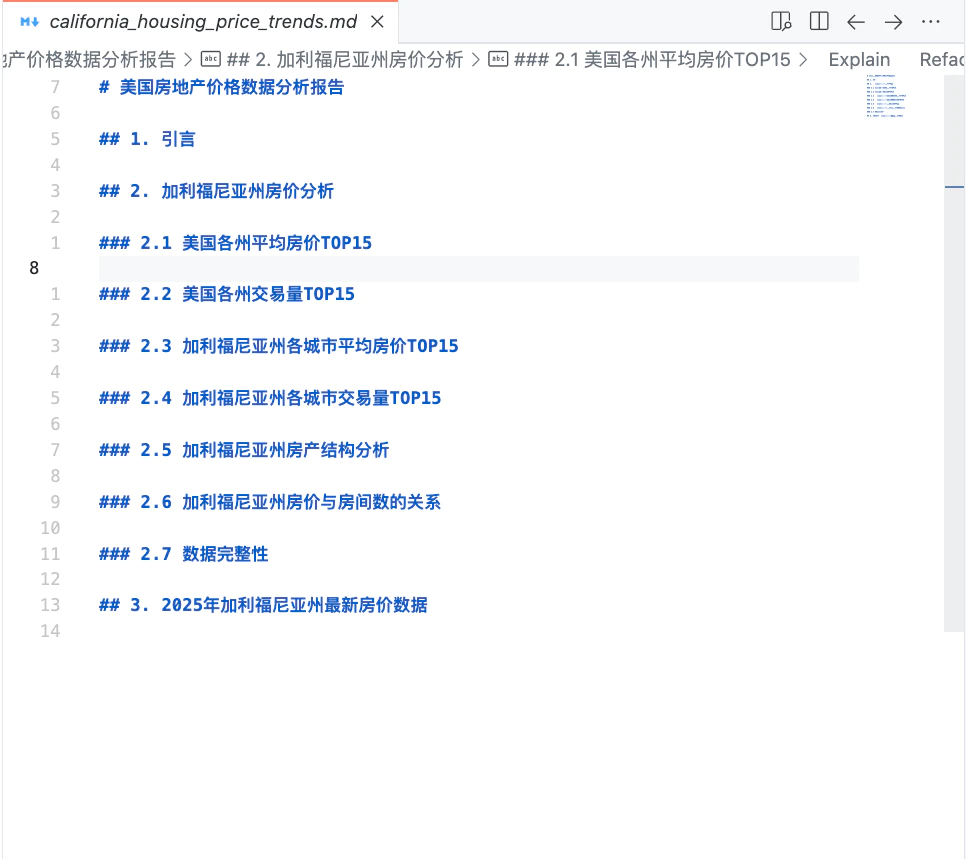
我提交给 AI 模型的 prompt 如下:
使用 sequential-thinking 思考并完成下面的工作:
使用 filesystem 工具读取 @california_housing_price_trends.md 文档中第二节的标题,根据标题内容使用 MySQL 工具依次查询数据库,并将查询结果添加到文档中
执行过程
可以看到 AI 模型根据我列出的 7 个标题,将任务拆分成了 7 步,依次根据每一步的标题来查询数据库。

完成查询后,修改了原文档的内容,将结果插入到对应的标题下:



作为检查,我将 AI 模型输出的 SQL 语句转化成标准的 SQL 语句(形如 { "query": "SELECT state, ROUND(AVG(price), 2) as avg_price\nFROM realtor-data\nGROUP BY state\nORDER BY avg_price DESC\nLIMIT 15;" }),自行执行数据库查询,得到的结果与它返回的结果一致。这表明结果并不是 AI 模型自己杜撰的。

结果评估
在这个场景中,AI 模型同样准确理解了我的指令,根据我在文档中列出的标题,使用 MySQL 工具从数据库获取了我想要的数据,并将结果插入到原文档正确的标题下。
小结
从上述两个场景实例中可以看出,借助 MCP,AI 模型可以真正完成我们想要它做的事情,而不仅仅局限于你问我答的单一对话场景。
MCP 服务还有很多,我在文中列出的场景尚显单薄,欢迎各位读友在评论区集思广益,将 AI模型 + MCP 的组合融入到自己的工作流中。
